飛躍的進化を遂げた音声認識技術の裏側と今後の動向に迫る!

近年、日常生活においてパーソナルアシスタントが当たり前のように使われ始めました。なかでもiPhoneの「Siri」や「Google Home」などの音声認識は、知りたいことやして欲しいことを声で伝えるだけで問いかけを理解し、即座に答えを出してくれます。こうした音声認識技術自体は古くから存在していますが、ここ数年の技術発展が著しく、自然な会話内の長文や騒がしい環境下での会話なども高精度の認識が可能となりました。一体、この分野で何が起きたのでしょうか。ここでは、音声認識技術の最近の進歩の裏側と、それによってもたらされるインパクトについて解説します。
Contents [hide]
認識率が急激に向上した音声認識技術
音声認識技術の認識率の向上は、目覚ましいものがあります。全米民生技術協会(CTA)によると、音声認識技術の単語誤識率は、1995年当時ほぼ100%に近い状態でした。ところが、2013年の統計では23%にまで下がり、今や人間とほぼ変わらないレベルに達したといえます。もちろん、このデータは英語における話で、日本語の音声認識技術の推移とは異なります。しかし、1990年代に登場したばかりの音声認識機能付きカーナビなどの、昔の音声認識を知る人にとって、今の技術はまさに隔世の感があるでしょう。

高度な音声認識機能を備えたスマートスピーカーが続々登場。
出典:bht2000 ? stock.adobe.com
音声認識が人と機械の距離を縮める
現在のような日常的に利用可能な音声認識技術が投入された機器の先駆けとして、2014年に米Amazon.com社が発売したスマートスピーカー「Amazon Echo」が挙げられます。この製品には、「Alexa」と呼ばれる音声認識と、対話の機能を持つパーソナルアシスタント機能が搭載されました。この機能はスピーカー操作のコマンド認識だけでなく、「今日の天気は」とか「部屋の灯りを消して」といった問いかけやお願いごとを理解し、すぐさま応えてくれます。Amazon Echoはネットに蓄積した情報やネットにつながる機器にアクセスできるという点において、もはや賢いスピーカーという枠を超えた、人と仮想空間をつなぐ入り口となる機器だったのです。
機能だけを見れば、パソコンのマウスやキーボードを操作したり、スマートフォンのタッチ操作をしたりしても同じようなことができるでしょう。しかし、人と人との自然なコミュニケーション手段である会話によって、仮想空間の情報や機能を使えるようになったことで、人と機械の距離がグンと近くなりました。実際に、パソコンやスマートフォンを使えない高齢者のなかには、一度スマートスピーカーを使うともう手放せなくなるという人がいます。このように、デジタル・ディバイドを解消する上で、音声認識技術は極めて重要な意味を持っているのです。
AIの発展が音声認識技術向上に一役買っている?
それでは、なぜ音声認識技術は近年これほど進歩できたのでしょうか。その背景には、ソフトウェア技術とハードウェア技術それぞれの進化があります。
まず、人工知能(AI)の技術、特にディープラーニング(深層学習)の進化が技術発展に大きく貢献しています。音声認識に応用する動きが活発化したことで、認識率は飛躍的に向上しました。AIは画像認識の分野でも圧倒的な認識率の向上をもたらしましたが、音声認識の分野でもブレークスルーとなったのです。
具体的に音声認識処理のどの部分にAIが使われるようになったのかを明確にするため、音声認識の処理の手順を簡単に説明します。
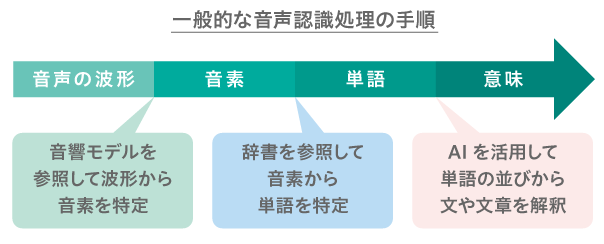
一般的な音声認識処理の手順。
音声認識技術は、音声をテキストに変換し、そのテキストの意味を解釈するまでが一連の流れです。その際、まずは音声の波形を細かく分割し、それぞれを分析して、どこが「あ」で、「い」で、「う」なのかを特定していきます。こうした、言葉の最小単位のことを音素と呼びます。
ところが、個々人の声質や声を発する環境によって、同じ「あ」でも波形が変わってしまいます。そこで、数千人分の様々な音声を統計処理し、音の波形の周波数成分や時間の変化の特徴から、どの音素を発しているかわかるようにモデル化しておきます。こうして作ったモデルのことを音響モデルと呼びます。ただし、音響モデルはあくまでも判定基準に過ぎません。認識対象の音声は、どの音素の音響モデルに最も近いのかソフトウェアで判定し、認識結果が決まるのです。
次に、認識した音素を並べて、辞書を参照しながら、「あした」とか「あめ」といった意味のある単語のどれを発しているのか、パターンマッチングします。さらに、その単語のつながりを解釈して、文や文章となった音声の内容を認識していきます。このような単語から本文内容を解釈する技術は、翻訳技術などにも使われているものであり、この分野でも主にAIが利用されています。かつて、高精度な音声認識は、操作コマンドのような特定の単語だけに限定されたものでした。しかし、AIを活用することによって、複雑な文や文章の内容を解釈できるようになったのです。
現在進行系で技術革新を遂げる音声認識
音声認識技術はまだまだ発展途上であり、現在も処理手順において様々なイノベーションが生まれています。中国のBaiduは、従来の音声認識処理の手順を見直し、AIの威力をフル活用した新たな技術「Deep Speech 2」を開発しました。これは音声波形から会話の内容をAIで一気に解釈しようとする技術です。
人間同士の会話では、従来の音声認識処理のような段階的な処理はしていません。特にネイティブの人は、文法なども意識することなく、音声の意味をそのまま解釈しています。Baiduの試みは、人間に近い自然な認識手法なのかもしれません。
また、音声認識処理の前半の音声波形から音素を特定する部分でも、誤認を引き起こす要因がたくさんあります。例えば、音声を取り込むマイクが発話者から離れていると、周辺の環境音がノイズとなって紛れ込み、音素を特定しにくくなります。そのため、多くの人が会話しているパーティー会場のような場面では、雑多に重なった音声波形の中から認識したい人の音声を分離しておく必要があります。

これまではパーティー会場のような雑多な会話が交じる環境での音声認識は難しかった。
出典:Rawpixel.com ? stock.adobe.com
このような問題の解決を図るため、最近では取り込んだ音に前処理を施して、周辺ノイズや他の人の声から話者の音声を分離できるようなマイクの構造の工夫も見られます。例えば、Amazon Echoは7個のマイクを搭載し、ひとつひとつのマイクがわずかな音の違いを拾い分ける高度なステレオマイクとして機能しています。この違いを利用して、発話者がいる方向を特定し、音源を分離しているのです。こうした技術のことを、ビームフォーミング技術と呼びます。さらに、Amazon Echoは元々スピーカーですから、マイクから拾った音の中から、自ら発している音楽の音を除外する機能も備えています。
ビームフォーミング技術が確立される以前はヘッドセットのマイクを使って口元で音声を拾わないと、正確な認識ができませんでした。しかし、この技術の効果は絶大で、今では環境音が混じりやすい6?9mもの遠方から語りかけても、音声を正しく認識できます。
また、Amazon Echoは、語りかける前にボタンなどを押す必要がありません。これは話者の音声を分離できているからこそ実現した機能です。これまでは、音声を正確に認識するために重要な話を聞かせることをボタンであらかじめ知らせて、機械の側に身構えてもらう必要がありました。現在では、機械へ自然に語りかけることができるようになり、パーソナルアシスタントの使い勝手が飛躍的に向上しています。
この他、音声を分離する技術 を別の用途に応用する動きとして、これまで捨てていた周辺の環境音から場の空気を読み取る技術の開発が進められています。これは何かを発表した時に起こる会場のどよめきや拍手、屋外での鳥や川のせせらぎの音などを加味して会話の内容を読み取れば、これまでよりも価値の高い情報の記録や活用ができるのではという発想から生まれた研究です。
人と人の言葉の壁を超える
多くのエンジニアにとって、音声認識技術を学び、使いこなすことのメリットは極めて大きいといえます。多機能だが、操作用のボタンやダイヤルが多すぎて使いにくい。そんな課題を抱えた機器はたくさんあります。人が日常的に使っているコミュニケーション手段である音声を使って操作できれば、誰もが機能を使いこなせるようになることでしょう。その応用分野は極めて広いといえます。
また、音声認識技術を活用した新しい応用も次々と現れています。今、最も期待されている応用技術が、自動同時通訳です。すでにその先駆けとなる製品が登場しており、ネット広告などで目にしたことがある人も多いと思われます。AIの進化によって、音声認識と翻訳の精度は目覚ましく向上しています。近い将来、日常的な会話の場面で言葉の壁がなくなる日が来るでしょう。
非英語圏の多くの人は、世界の中で仕事をするために英語やその他の外国語学習に膨大な時間と費用を投じています。これは、大きなハンディキャップです。また、言葉の壁によるお互いの不理解が、争いの種を生むこともあります。自動同時通訳が実現すれば、こうした問題が解消に向かうかもしれません。2020年の東京オリンピック/パラリンピックは、時期的にも自動通訳技術の本格的な活用を目指す絶好の目標です。それに向けて、多くの製品開発や実証実験などがすでに始まっています。
\ SNSでシェアしよう! /
【はたラボ】派遣のニュース・仕事情報・業界イロハ|派遣会社・人材派遣求人ならパーソルクロステクノロジー |IT・Web・機電の派遣求人ならパーソルクロステクノロジーのエンジニア派遣の 注目記事を受け取ろう
【はたラボ】派遣のニュース・仕事情報・業界イロハ|派遣会社・人材派遣求人ならパーソルクロステクノロジー |IT・Web・機電の派遣求人ならパーソルクロステクノロジーのエンジニア派遣

この記事が気に入ったら
いいね!しよう
【はたラボ】派遣のニュース・仕事情報・業界イロハ|派遣会社・人材派遣求人ならパーソルクロステクノロジー |IT・Web・機電の派遣求人ならパーソルクロステクノロジーのエンジニア派遣の人気記事をお届けします。
-
気に入ったらブックマーク!

- フォローしよう! Follow @persolcross
